- 登入
- 註冊

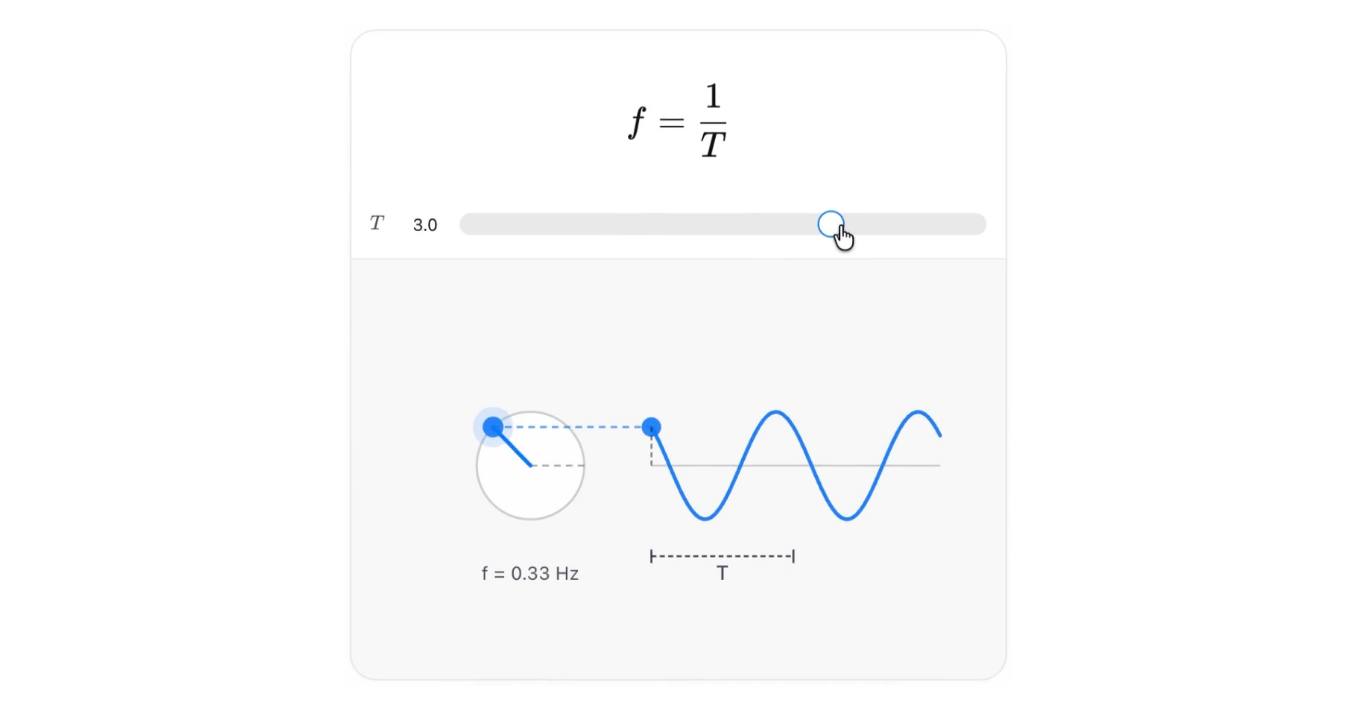
為什麼會有AI幻覺?看看OpenAI怎麼說🌠
快訊:把照片變公仔的Nano Banana模型、 EmbeddingGemma 開放式嵌入模型、OpenAI擬推出家長監控功能、Lovable 讓你一鍵生成網頁、Supabase 開源後端平台



有沒有注意到最近網路上出現不少擬真模型公仔的圖片?最近很火紅的 Gemini 模型 Nano Banana(奈米香蕉)讓你在 Google AI Studio 上傳照片後,再加上一段簡單指令,就能生成超擬真的 3D 模型公仔圖片!

Nano Banana 的正式名稱為 Gemini 2.5 Flash Image,特色在於「保持物件原始風格」的能力,能準確保留使用者提供的圖片中原始物件的特色,大大減少了過去在以圖生圖情境中,經常遇到的服裝、髮型、特徵改變等問題。不僅僅是一張照片生成一張圖片,Nano Banana 也能透過簡單的文字指令,完成多張圖片的融合與局部調整。


Google 推出了 EmbeddingGemma 開放式嵌入模型,專為手機或電腦的 AI 應用程式設計。EmbeddingGemma 的核心功能是將文字(如訊息、電子郵件或筆記)轉換為獨特的數字向量(稱為「嵌入」),讓電腦能理解這些文字的意義和它們之間的關係。主要特點與優勢包括:
- 小巧高效:擁有3.08億個參數,經過優化,運行時僅需不到 200MB 的記憶體,非常適合在手機、筆記型電腦等日常硬體上直接運行。
- 隱私與離線能力:EmbeddingGemma 在你的裝置上直接處理資料,讓資料留在本地不外流,即使沒有網路也能運作。
- 高品質與多語言支援:它在綜合性的文字嵌入評估基準(MTEB)中表現出色,支援超過100種語言的訓練,提供高品質的文字理解能力。
- 高度客製化:透過 Matryoshka Representation Learning (MRL) 技術,開發者可以調整輸出嵌入的維度(從768到128),以平衡品質與速度 / 儲存成本。
- 廣泛整合:EmbeddingGemma 已支援多種流行的開發工具和平台,方便開發者快速整合。
應用場景方面,EmbeddingGemma 能夠為行動裝置的的生成式AI體驗提供強大動力,例如實現本地文件的語義搜尋、客製化分類、建立離線 AI 聊天機器人;以及透過檢索增強生成(RAG)管道提供更個人化和相關的回應,例如 AI 會理解用戶跟它要水電工的電話,是為了解決家裡漏水的問題。


ChatGPT 被指控鼓勵一名少年自殺,OpenAI 因此面臨訴訟。為了應對這個案件,OpenAI 推出了新的家長控制措施,包括當系統偵測到青少年處於「嚴重困擾」時,會向家長發出通知。然而,死者家庭的律師將這些措施批評為「危機管理」,並呼籲將該聊天機器人下架。與此同時,Meta 也宣布會重新訓練模型,不讓自家的 AI 聊天機器人 (Meta AI) 與青少年討論自殺、自殘或飲食失調等敏感話題。但是有專家指出,目前 AI 聊天機器人對此類自殺相關詢問的回應,還是有回答不一致的狀況。

Lovable 是最近越來越火的 vibe coding 工具,讓每一位使用者都能透過自然語言描述,來建立功能完整的應用程式和全端網站。只需要在聊天介面中描述你的想法,平台就能將把你的想法轉化成現實!
- 技術基礎:在前端使用 React 和 Vite 框架,確保應用程式功能強大、響應迅速且流暢。後端則採用 Supabase,一個開源解決方案,提供資料庫儲存、用戶認證和雲端功能等服務。
- 豐富功能整合:支援數據持久性、用戶認證、電子郵件提醒、付費訂閱(透過 Stripe)等功能。它還能將應用程式轉換為可在行動裝置上安裝的漸進式網路應用程式 (PWA)。
- 版本控制與協作:雖然 Lovable 不允許直接編輯介面中的程式碼,但可以將應用程式的程式碼連結到 GitHub 儲存庫,實現協作開發和版本控制。


Supabase 是一個開源的後端即服務(BaaS)平台,提供 PostgreSQL 資料庫,被視為 Firebase 的開源替代方案。它提供托管資料庫、用戶驗證、即時訂閱(Realtime)、檔案儲存(Storage)、自動生成的 REST/GraphQL API,以及可部署至邊緣節點的無伺服器函式(Edge Functions)等功能。
Supabase 的特色在於快速上手、功能齊全,並允許自行託管來避免廠商綁定,適合開發 MVP、個人專案或具規模成長潛力的應用程式。


由 OpenAI 研究團隊,包含電腦科學家 Adam Kalai 等多位貢獻者,發表的這篇文章深入探討了人工智慧語言模型(如ChatGPT)中一個核心挑戰:「幻覺」。所謂的「幻覺」,是指模型會非常自信地生成聽起來合理,但實際上是錯誤的資訊 (若無其事地說瞎話),即使是最新的 GPT-5 模型也會這樣。這項研究指出,幻覺之所以難以根除,主要是因為目前的訓練和評估方式,無形中獎勵了模型去「猜測」答案,而非直接承認自己不知道。接下來,我們會把這篇文章換句話說成比較容易理解的版本,說明 OpenAI 如何解析這些幻覺的根源,並思考如何讓 AI 的回應變得更加可靠。
什麼是語言模型幻覺? 想像一下,當你問一個非常聰明的人一個問題,而他其實不知道答案,卻還是非常自信地給你一個完全錯誤的答案。這就是語言模型(例如 ChatGPT)發生「幻覺」的情況。這些模型會生成聽起來很合理,但實際上是錯的資訊。例如,當被問及某位作者的博士論文標題或生日時,模型可能會給出多個不同,但都是隨機亂湊的標題跟日期。
為什麼會出現幻覺?
- 「選擇題考試」的副作用:
- 目前的評估方式就像一場多重選擇題考試,如果你不知道答案,亂猜一個答案可能偶然猜對,但留空就一定拿零分。
- 因此,模型在訓練時,如果只看重「答對率」(準確度),就會被鼓勵去「猜測」答案,而不是誠實地說「我不知道」。
- 在數千個題目中,偶爾猜對一兩個答案,會讓模型在分數上看起來比那些「懂得承認自己不會」的模型表現更好。在成績至上的觀念下,會讓模型寧願去亂猜不會的題目,而不是去坦承自己不知道。
- 來自「預測下一個字」的訓練方式:
- 語言模型在訓練初期(稱為「預訓練」)是透過預測大量文本中的下一個字來學習的。
- 這個過程沒有「對/錯」的標籤,模型只是學習流利語言的運作模式。
如何減少幻覺?
- 改變「計分方式」:一個直接的解決方法是:對「自信的錯誤」施加比「承認不確定性」更重的懲罰。同時,對於適當地表達不確定性給予部分分數。這就像某些標準化考試會對錯誤答案扣分,或對留空不答給予部分分數,藉此阻止盲目猜測。重點是,所有主要評估指標都需要重新設計,鼓勵 AI 表達不確定性,而非獎勵那些幸運猜對的答案。
- 理解幻覺的本質:
- 誤解一:提高準確度就能消除幻覺。事實:準確度永遠不會達到 100%,因為有些問題天生就是無法回答的。
- 誤解二:幻覺是不可避免的。事實:不是,因為語言模型可以在不確定時選擇不回答。
- 誤解三:只有大型模型才有能力避免產生 AI 幻覺。事實:小型模型更容易知道自己的極限。例如,一個不懂毛利語的小型模型會直接說「我不知道」,而一個懂一些毛利語的模型則需要判斷其信心程度(*註)。
- 誤解四: 幻覺是語言模型的神秘故障。事實:OpenAI 自稱已經瞭解了幻覺會產生的機制。
- 誤解五: 為了衡量幻覺,我們只需要一個好的幻覺評估工具。事實:幻覺評估工具確實已經發布。然而,光有好的「幻覺評估」是不夠的,因為目前大多數評估 AI 表現的方式,都像是一個只看答案對錯的考試。這種考試方式會「懲罰」AI承認不確定(就像考試留白得零分),卻「獎勵」AI 去猜測(即使是瞎猜,猜對了也能得分)。因此,即使有再好的幻覺評估工具,也難以對數百個傳統的準確性評估產生影響。相反地,所有主要的評估指標都需要重新設計,以獎勵 AI 在不確定時坦承表達。
OpenAI 表示他們正在努力減少模型產生自信錯誤的機率,最新的模型 GPT-5 已經有比較低的幻覺率啦。總結來說,語言模型的幻覺就像一個太想考高分而亂猜答案的學生,因為目前的考試制度(評估方式)獎勵「猜對」而不是「誠實承認不知道」。同時,模型在學習過程中,對於那些沒有明顯規則的「冷門知識」,也容易因為缺乏足夠的明確資訊而「編造」答案。解決之道就是改變考試規則,讓「承認不知道」比「自信地說錯」更有利,這樣模型就能學會更加謙遜跟可靠。
💡註:一個略懂毛利語的模型處於一個比較尷尬的狀況。它可能在訓練數據中看過一些毛利語的詞彙、語法結構或相關上下文,所以它不是完全空白。這就像一個只學過幾句法語的人。
當它被問到毛利語問題時,它就不能像第一個模型那樣直接說「我不知道」。它必須根據自己有限的知識,去評估它生成答案的「可靠程度」有多高。也就是說,它需要「判斷其信心程度」。
→如果它覺得自己有足夠的信心,可能會嘗試給出一個答案。
→如果它判斷自己的知識不足,信心程度不高,它就應該選擇承認自己不會或尋求澄清,而不是冒險給出一個錯誤但聽起來很自信的「幻覺」答案。