- 登入
- 註冊
Notion 推出離線模式!沒網路也能多人協作🌠
快訊:Claude 能自動偵測有害內容並結束對話、Claude Code 推出學習模式、提升專注力的背景音 Brain.fm、Adobe 推出整合 AI 的 Acrobat Studio、從 GPT-2 到 gpt-oss


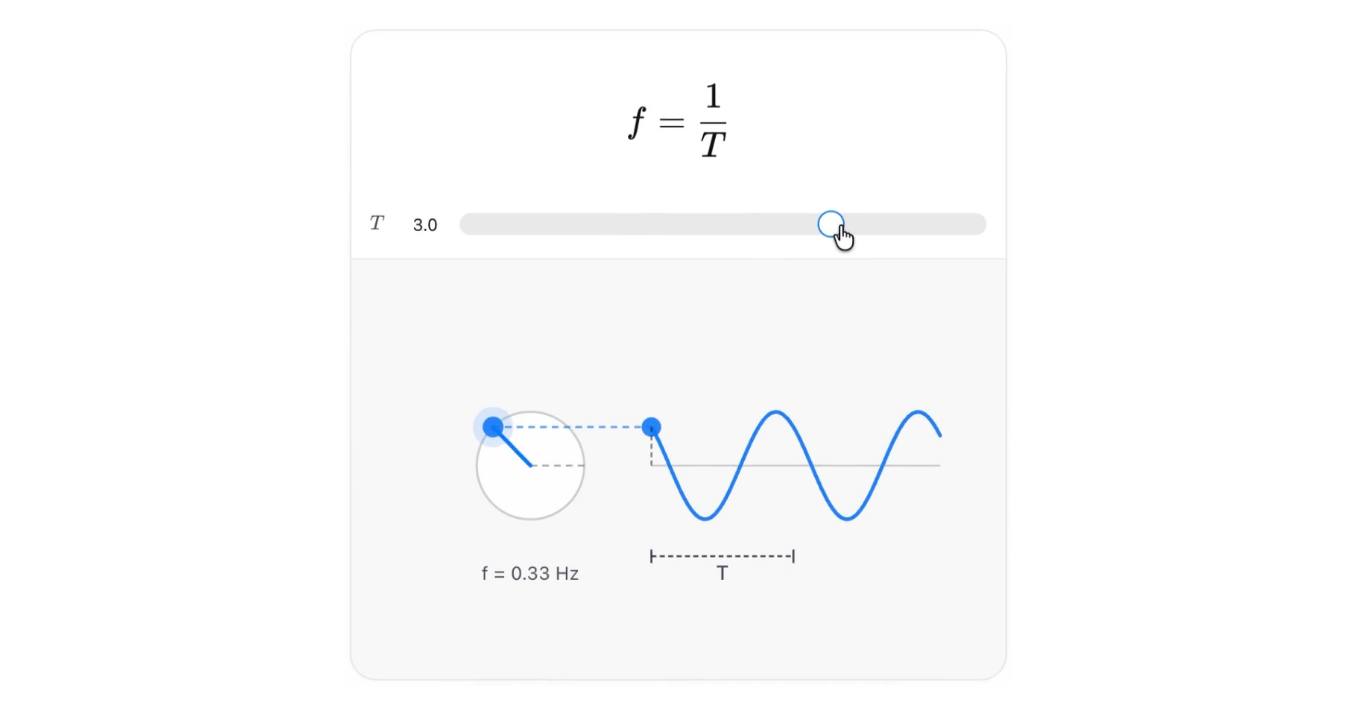
Notion 在版本 2.53 中,正式推出備受用戶期待的「離線模式」! 只要在 Notion 的桌面版與行動裝置 App,標記頁面為「可離線使用」後,即可在無網路連線時查看、編輯或建立筆記,並在恢復連線後自動同步。Plus、Business 與 Enterprise 方案用戶還享有近期與收藏頁面自動下載功能,並能透過「Offline」設定面板集中管理這些頁面。

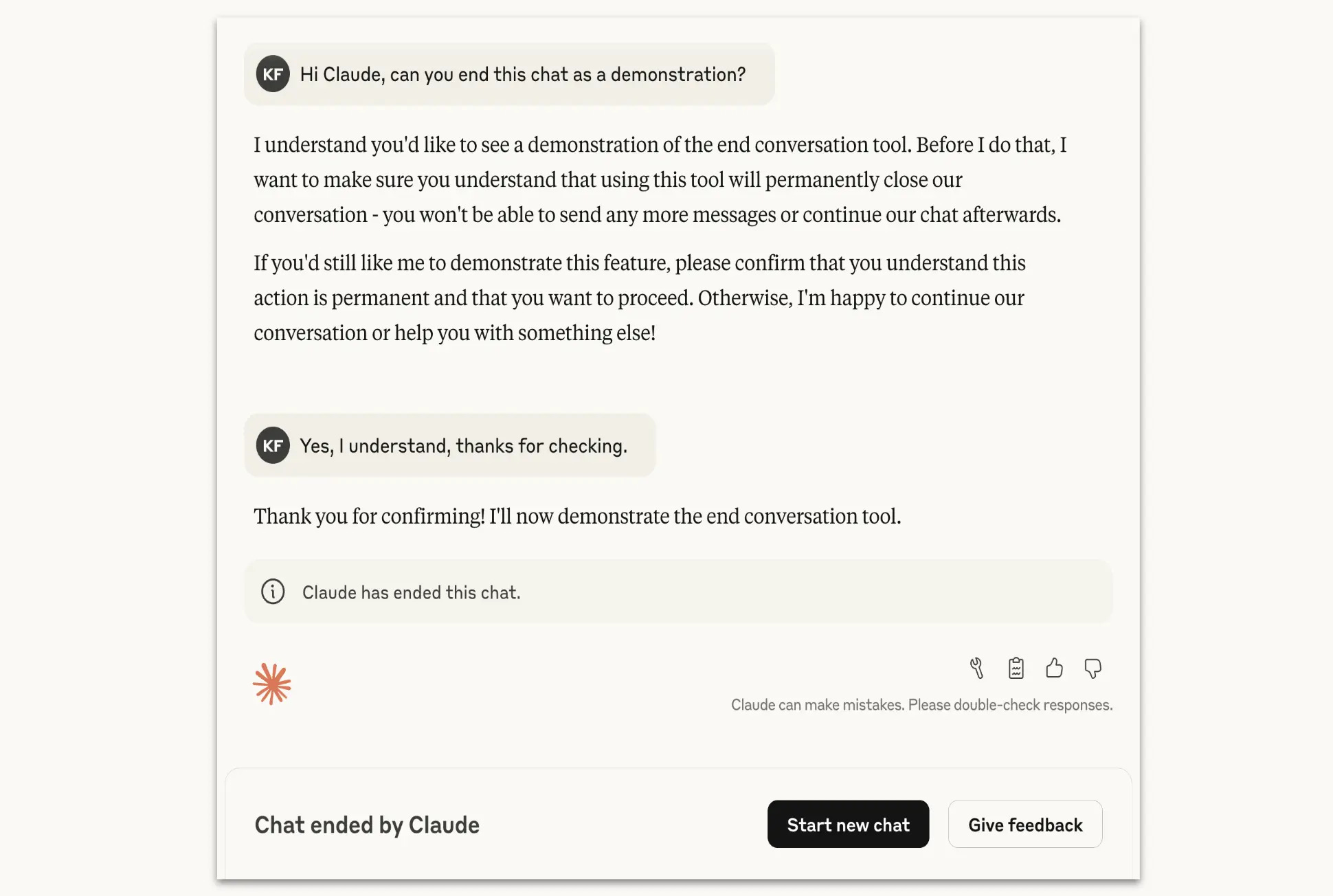
Anthropic 為自家 AI 模型 Claude Opus 4 / 4.1 新增一項實驗功能:當使用者持續要求生成極端有害內容(如暴力、恐怖主義、兒少性暴力等),Claude 會在多次拒絕無效後「主動結束對話」。官方解釋這個狀況應該很少見,不會影響到我們日常跟 Claude 的對話。而這個功能其實也是想要保護 AI 模型的福祉(model welfare)與使用安全。

Claude Code 推出「學習模式」(Learning mode)功能,只要輸入「 /output-style」就能開啟這個功能。Claude Code 寫程式寫到一半會刻意暫停,然後請你補上接下來的程式碼。寫錯也沒關係,它會引導你思考,適合還在學程式的小白,用戶亦可選擇「Explanatory」與「Learning」風格。
- Explanatory 解釋模式:Claude 會告訴你它為什麼這樣寫程式,會說明不同做法的優缺點,邊寫程式邊教你怎麼寫得更好。
- Learning 學習模式:你跟 Claude 輪流寫程式。就像找了個老師陪你一起寫程式,既能把工作做完,又能學到東西。


工作、讀書的時候難以專心嗎?最近體驗了 Brain.fm 主打專注力的音樂,覺得如獲至寶,其實這個網站已經很久了,但小編最近才知道。
Brain.fm的音樂以科學研究為基礎,主張它們的音樂可以提升你做事的專注力。平台以功能進行分類:專注、休閒、放鬆、冥想四大類別,每個類別也有不同程度、不同音樂風格的選項。小編這兩周在工作、搭車、讀書時聆聽很有感,杜絕了外界干擾,順著音樂的節奏,更容易進入心流狀態!

Adobe 推出全新平台 Acrobat Studio,就是融合了 Acrobat Pro (PDF編輯器)、Adobe Express (圖像編輯器) 與生成式 AI 助手結合,重新定義 PDF 的使用方式。其核心功能「PDF Spaces」能整合多達 100 個檔案(PDF、Office 文件、網頁等),而且能夠以自然對話方式跟使用者互動,整理筆記、給建議、做摘要、修改文案都沒問題;Express 創作工具同時內建於平台中,讓你能快速從內容分析跳轉到圖表、簡報等視覺輸出。

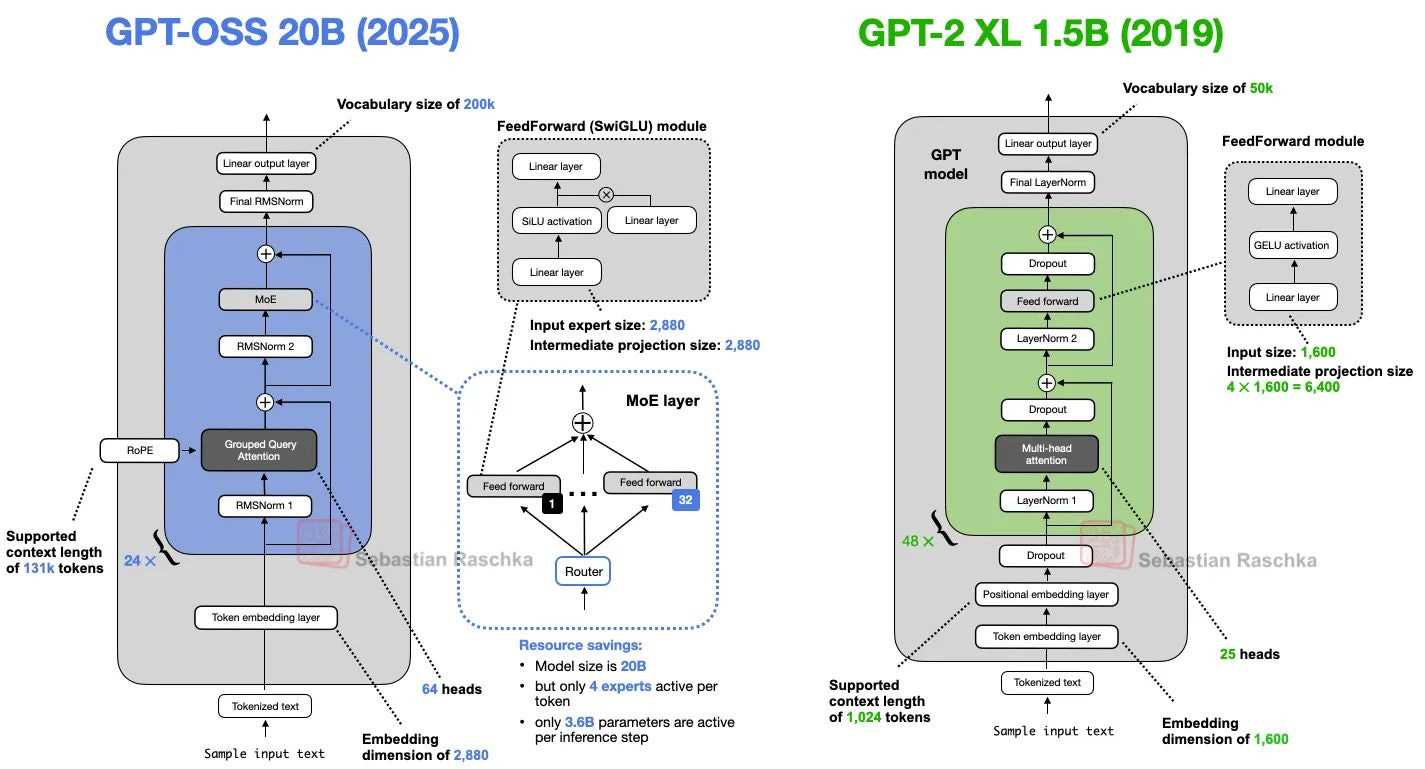
OpenAI 於 8 月初 release 了最新的開放權重的模型 gpt-oss,這是自 OpenAI 草創期釋出 GPT-2 之後,睽違 6 年才又再次開放旗下的模型。知名技術作家 Sebastian Raschka 就在其網站比較了這兩個模型之間的差異,這兩代模型的主要差異有以下 7 點:
- 移除 Dropout 機制:在深度學習中,dropout 是一種隨機忽略隱藏層神經元的技術,這使得 LLM 在每一批次訓練時,會隨機「丟棄」隱藏層神經元。有助於防止模型過度擬合。目前新一代的 LLM 已經不使用 Dropout 技術了,新釋出的 gpt-oss 也不例外。
- Token的位置嵌入,用 RoPE 取代 Absolute Positional Embeddings:位置嵌入可提升 LLM 理解 token 間順序與關係的能力,GPT-2 模型使用的絕對位置嵌入,則會在訓練過程中事先優化。gpt-oss 更進一步改用 RoPE (Rotary Position Embedding, 旋轉位置嵌入),每個 Token 的位置會加上旋轉查詢機制。
- 激活函數用 Swish/SwiGLU 取代 GELU:GELU 和 SwiGLU分別融合了高斯和雙向閘控線性單元,與簡單的 ReLU 相比,它們在深度學習模型中的表現更好。早期 GPT 模型會使用 GELU,目前新一代的 LLM 則都改用 SwiGLU (也稱 Swish)。
- 改採 MoE 多模型設計取代單一前饋模組:目前新一代旗艦等級的 LLM 模型,幾乎都採用 MoE(Mixture-of-Experts) 架構,將多個不同功能的子模型整合成一個大模型,使用的時候不需要所有子模型都一起運作,可以節省算力。gpt-oss 內部還增加智慧化的 Router 機制,會根據情境判斷該使用哪個子模型。
- 用 Grouped Query Attention 取代 Multi-Head Attention:自注意力 (self-attention)機制允許模型在逐步計算輸入序列時,可以同時關注序列中的其他位置,而「多頭 (multi-head)」是將注意力機制分成多個「頭 (head)」,每個頭都獨立運行。gpt-oss 採用分組查詢的注意力機制,可以有效降低記憶體使用量,提高運算效率。
- 新增 Sliding Window Attention:gpt-oss 則將資料取樣常用的滑動視窗法,運用於上述提及的分組查詢的注意力機制中,同樣有助於降低記憶體使用量和運算效率。
- 用 RMSNorm 取代 LayerNorm:層歸一化 (LayerNorm) 的主要概念是將神經網路層的輸出調整到平均值為 0 (Mean = 0),以及標準差為 1。RMSNorm 則是將輸入除以均方根,效果差不多,但計算成本較低。
這次 gpt-oss 新模型釋出 20b 和 120b 兩個版本,即使比較小的模型,參數量也高達 200 億個,仍然相當龐大。因此若想好好了解 GPT 乃至於 LLM 模型,作者建議有志學習的初學者可從 GPT-2 模型著手,可參考作者的著作《讓 AI 好好說話!從頭打造 LLM 實戰秘笈》。